|  | |
| Sommaire | 2. Portails |
DEMOLI
|
GEREC-F DEMOLI |
Pour se faire une première idée du genre de choses que l'on peut trouver sur tel ou tel sujet, rien de tel que de commencer par les bons vieux moteurs de recherche. Tout le monde connaît maintenant le principe : on tape quelques mots-clés, et on récupère les documents accessibles par internet et contenant ces mots-clés.
Autrefois (autrefois, de nos jours, veut dire : il y a dix ans), quand on tapait un mot-clé sur http://www.altavista.digital.com, ...
|
|
|
Instantané de la page d'accueil d'Altavista le 22 octobre 1996 (archivé par le projet Wayback Machine, http://www.archive.org) |
on récupérait quelques dizaines de documents, presque tous situés sur les serveurs des grandes universités — certains sérieux, d'autres écrits par des étudiants. Mais quoi qu'il arrive, on récupérait du texte. Aujourd'hui, le monde est ainsi fait que quel que soit le mot-clé choisi, on a de fortes chances de récupérer quelques centaines de milliers de documents, dont la moitié seront des publicités en format Macromedia Flash pour acheter des aphrodisiaques au Canada.
Il n'y a hélas pas de solution absolue à ce problème, et il faut, sans se décourager, apprendre à « ruser » avec les requêtes pour affiner peu à peu la pertinence des résultats obtenus. Quelques pistes de départ pour apprendre à cibler sa façon de chercher sont proposées plus bas (§7).
En attendant, on peut commencer à chercher des informations avec les moteurs de recherche classiques — l'expérience venant de toute façon peu à peu. Il n'est généralement pas utile d'utiliser trente moteurs de recherche différents pour être sûr d'être exhaustif, car on récupérera probablement en gros toujours les mêmes documents ; cela étant, les ensembles de documents qu'indexent les différents moteurs ne coïncident pas forcément strictement, et il n'est pas inutile de se rappeler qu'il n'y a pas que Google qui existe (même si c'est tout de même un rudement bon premier choix).
Liens vers quelques moteurs de recherche :
Google, disponible à l'adresse : http://www.google.com.
|
|
|
Page d'accueil de Google en 2005 |
Considéré comme la référence en matière de recherche d'information sur internet, ce moteur a acquis sa réputation — justifiée — grâce à la sobriété de son interface et à la pertinence des résultats qu'il offrait en haut de liste. Cette pertinence vient de l'algorithme de classement de Google, qui combine au taux d'adéquation document/mot-clé une mesure intégrant le nombre de liens qui pointent déjà sur la même page : c'est donc une « prime » offerte aux sites déjà reconnus. Cette prime à la célébrité est en général pertinente. Le revers de la médaille : c'est un système qui s'auto-entretient, et vous ne voyez plus sur Google que les sites sur lesquels pointent d'autres sites reconnus par Google !
Altavista, disponible à l'adresse : http://www.altavista.com.
Le doyen des moteurs de recherche a encore de beaux restes, et a
continué à entretenir l'une des bases d'indexation les plus larges du
web. Longtemps resté indispensable parce qu'il autorisait les
recherches booléennes (cf. §7) alors que Google
ne le faisait pas, il n'a maintenant plus l'exclusivité de cette
fonction. L'un des avantages d'Altavista, pour les chercheurs
débutants qui ne maîtrisent pas énormément de langues étrangères, est
qu'il intègre un moteur de traduction automatique facilement
accessible depuis n'importe quelle page de résultats de
recherche. Vous pouvez donc, par exemple, chercher des documents en
allemand concernant votre thème d'intérêt (N.B. pour traduire vos
mots-clés en allemand, utilisez http://dict.leo.org ;
pour avoir une liste de divers dictionnaires pour diverses langues,
regardez le site http://www.yourdictionary.com/),
et vous avez la certitude, à défaut d'en obtenir une bonne traduction,
de savoir en gros de quoi ils parlent.
Alltheweb, disponible à l'adresse : http://www.alltheweb.com, a pour lui sa rapidité.
À côté des moteurs de recherche proprement dits, il existe ce qu'on appelle des « annuaires web », dont le plus connu est Yahoo! (http://www.yahoo.com). La différence est qu'au lieu de laisser un programme (appelé « crawler », mot anglais évoquant l'idée d'une chose qui fait son chemin discrètement, en rampant) parcourir le web automatiquement pour trouver des adresses URL valides, et un autre programme indexer toutes les pages par les mots qu'elles contiennent, l'annuaire web range les sites dans des catégories prédéfinies, et que ce rangement est effectué par des experts humains.
La perte en couverture (un groupe d'experts humains, aussi efficace soit-il, ne peut faire le même travail que des procédures automatisées) est compensée par le gain en fiabilité des indications fournies. En effet, vous pouvez tromper un indexeur automatique en mettant en ligne une page de publicités pour des sites pornographiques, et en insérant dans la partie « mots-clés » de cette page une liste de 1000 mots choisis parmi les plus courants dans la langue française (c'est une technique très utilisée) ; mais vous ne pouvez pas tromper l'expert humain, employé par Yahoo!, qui viendra valider votre site.
Récemment, le moteur de recherche Google a lui aussi ouvert un
service d'annuaire web. On y trouve notamment un catalogue très
complet des ressources de documentation scientifique en libre accès,
accessible à l'adresse :
http://directory.google.com/Top/Science/Publications/Archives/Free_Access_Online_Archives/.
Si l'on ne sait pas quel moteur de recherche choisir, et que les résultats de plusieurs de ces moteurs sont potentiellement intéressants, on peut consulter un métamoteur, interface qui consulte plusieurs moteurs et/ou annuaires en leur soumettant les mêmes mots-clés, et renvoie à l'utilisateur un classement fondé sur une mesure commune de pertinence des documents. L'exemple-type de métamoteur disponible en ligne est Metacrawler : http://www.metacrawler.com.
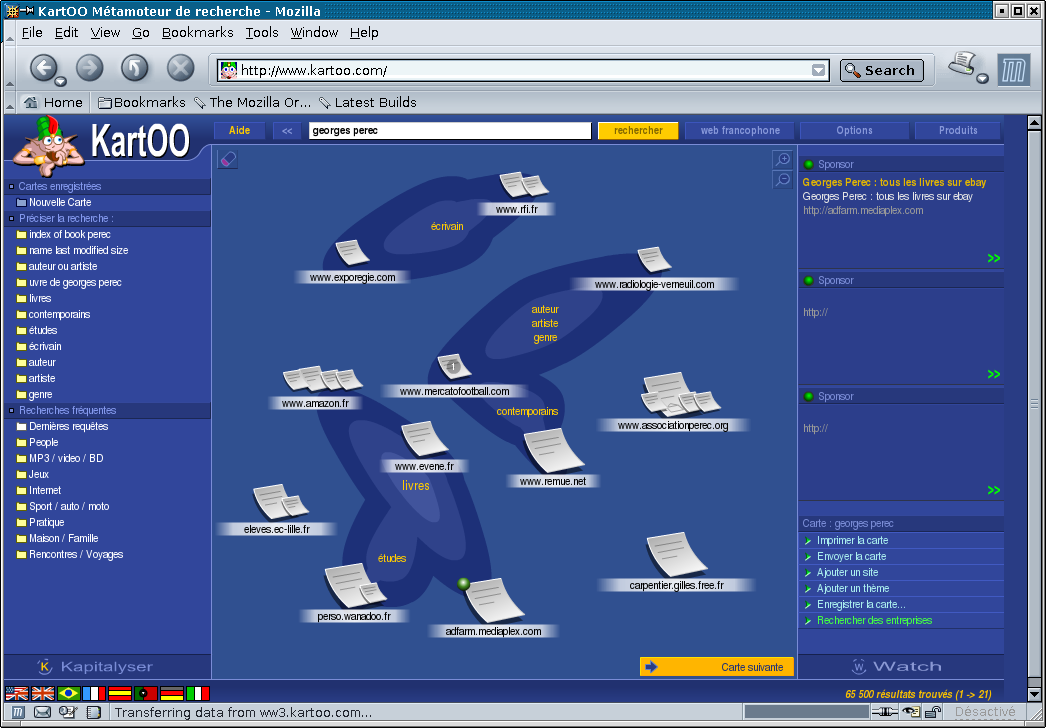
KartOO (http://www.kartoo.com), proposé par une petite société française basée en Auvergne, offre un modèle de recherche assez original. Ce métamoteur produit automatiquement, à partir de vos mots-clés, des cartes interactives de certaines « régions » de la Toile. Vous retrouvez sur ces cartes des « grappes » de sites contenant vos termes de recherche, et connectés entre eux. Les résultats de votre recherche, au lieu d'être livrés en vrac, sont donc organisés visuellement, sur un graphique en deux dimensions, pour refléter de grandes composantes connexes, thématiquement cohérentes, du web. Au centre de ces grappes, Kartoo affiche également des mots-clés supplémentaires, retrouvés sur les différents sites représentés à proximité : ils représentent en quelque sorte l' « orientation thématique » spécifique de la grappe située sous le curseur, par rapport à la thématique commune sous-jacente à l'ensemble du graphe (qui est bien sûr déterminée par vos termes de recherche initiaux). En cliquant sur l'un de ces mots-clés complémentaires, vous le rajoutez à vos termes de recherche, et le système bâtit une nouvelle carte, plus détaillée, afin de tenir compte de cette nouvelle dimension de la recherche.
|
|
|
Exemple de carte interactive KartOO |
Il existe également des programmes téléchargeables sur PC et qui font localement, en tant que programmes « clients », ce travail de méta-recherche. Exemple : Copernic.
La recherche sur la Toile est une expérience indispensable pour découvrir des pistes concernant le sujet qui vous intéresse, mais il ne faut surtout pas s'en contenter.
Tout d'abord parce que les publications les plus sérieuses sur un sujet donné sont en général éditées ; c'est-à-dire : relues, validées par un comité éditorial, puis publiées sous un format papier classique (et, naturellement, payant). Or les publications éditées qui sont diffusées sous une forme payante (livres, articles publiés dans une revue scientifique ...) ne sont en général pas diffusées en même temps gratuitement sur le Web, pour des raisons compréhensibles de valorisation du travail d'édition.
Sur ce terrain, il est d'ailleurs à noter que grâce à l'activisme d'un réseau international de chercheurs militant pour le libre accès à l'information scientifique, un certain nombre de revues scientifiques ont pris la décision d'autoriser les auteurs, parfois au terme d'un délai de primeur fixé à quelques mois, de pratiquer l' auto-archivage, c'est-à-dire de stocker s'ils le souhaitent une version électronique de leur article sur le site web de leur institution, ou sur un site d'archives scientifiques. La liste des éditeurs de revues acceptant la pratique de l'auto-archivage des « pre-prints » (versions d'articles non encore éditées) ou des « post-prints » (versions définitives des articles, après publication), tenue à jour dans le cadre du projet RoMEO (Rights MEtadata for Open archiving), est disponible sur le site du SHERPA, à l'adresse : http://www.sherpa.ac.uk/romeo.php?all=yes
Il existe par ailleurs un certain nombre de sites qu'on désigne sous le terme de « revues en lignes » (cf. ci-dessous, §3.1), et qui publient des articles scientifiques. Ces sites fonctionnent, pour ce qui est du processus de relecture et de validation scientifique, exactement de la même manière qu'une revue classique : les articles, avant d'être publiés, sont relus et évalués par un comité scientifique qui garantit la qualité des travaux. La seule différence avec les revues « papier » concerne bien entendu le support de diffusion, et parfois la périodicité (une revue électronique n'est pas obligée d'attendre des échéances de termes fixés à l'avance pour publier en une seule fois tous les articles accumulés entretemps : elle peut se permettre de publier chaque article dès qu'il sort du cycle de relecture et de validation). Mais par ailleurs, les revues en ligne dignes de ce nom sont ni plus ni moins que des revues.
En-dehors de ces cadres décrits succintement ci-dessus (pour résumer : les cas où on trouve, accessibles à travers la Toile, des publications scientifiques par ailleurs tout à fait classiques), il faut garder à l'esprit qu'une « page web », en soi, n'a aucune valeur de référence scientifique. Cela ne veut bien sûr pas dire qu'on ne trouve rien d'intéressant sur la Toile (on peut y trouver des cours, des textes de vulgarisation, des articles de Wikipédia rédigés [parfois mais pas toujours !] par des personnes compétentes ...), mais cela veut dire que tout ce qu'on y trouve n'est pas intéressant.
La Toile n'est pas une bibliothèque. On n'y trouve pas que des livres choisis à l'avance, soigneusement catalogués et rangés. On y trouve de tout, du meilleur comme du pire, sans indication systématique de l'origine de l'auteur de chaque document, de sa qualification, de ses compétences. Il faut donc apprendre à s'en servir pour ce qu'elle apporte en termes d'immédiateté d'accès à l'information (et qui est énorme : cela constitue, en quinze ans, l'un des progrès les plus considérables de l'histoire de la connaissance), mais avec discernement. Vous trouverez plus bas (§6.2, Caveat, et §7.3) quelques indications supplémentaires sur les manières de repérer l'information sérieuse et l'information pas sérieuse sur internet.
Contact : |
Pascal Vaillant |
( ) |