|  |  |
| 6. BDD biblio | Sommaire | Aller plus loin |
DEMOLI
|
GEREC-F DEMOLI |
Cette section est une présentation rapide, et sans prétention à la complétude, de quelques concepts et méthodes utiles dans le domaine de la recherche d'information.
Si vous ne baignez pas encore dedans, ce sera bientôt le cas : de nos jours, toute méthode de recherche d'information traduit ses résultats en termes de précision et de rappel ; et comme tout, par ailleurs, s'exprime en termes de recherche d'information — c'est à la mode —, en fait, tout s'exprime, ou s'exprimera bientôt, en termes de précision et de rappel. Plus un article scientifique, dans quelque domaine que ce soit, n'a de chances d'être accepté par une revue ou une conférence s'il ne comporte pas un ou deux petits tableaux résumant des résultats en termes de précision et de rappel, quel que soit par ailleurs le sujet. Alors, si vous ne voulez pas passer pour un benêt au prochain réveillon en famille, familiarisez-vous vite avec ces notions-clés : vous pourrez étonner votre oncle en lui parlant du mauvais rappel de son procédé de pressage des citrons.
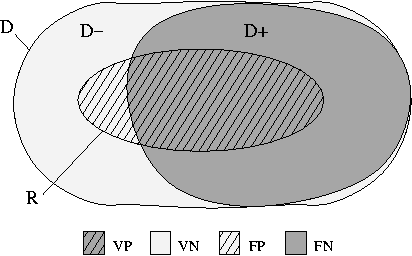
Toute recherche d'information se fait sur une base réelle de documents accessibles, ensemble fini mais peut-être très grand que nous appelons D.
Si vous faites une recherche, c'est que vous avez (probablement) un centre d'intérêt particulier. Dans l'ensemble de tous les documents possibles, il y en a donc qui sont susceptibles de vous intéresser, parce qu'ils relèvent réellement de vos thèmes d'intérêt particulier ; appelons ce sous-ensemble intéressant D+. Par ailleurs, le reste des documents, D–, est l'ensemble des documents qui ne tombent pas dans votre thème d'intérêt. En supposant que le critère de distinction est binaire, ces deux sous-ensembles forment une partition de l'ensemble total des documents, c'est-à-dire que : D+ ∪ D– = D, et que D+ ∩ D– = Ø. On appelle souvent les documents de D+ les documents positifs et les documents de D– les documents négatifs.
Lorsque vous faites concrètement une recherche d'information, vous espérez que le système que vous utilisez va vous trouver tout ce qui vous intéresse, et ne pas vous faire perdre votre temps avec des documents qui ne vous intéressent pas. En d'autres termes, vous voulez qu'il vous retrouve l'ensemble des documents de D+, et qu'il laisse de côté les documents de D–. En pratique, le système vous donne un ensemble de résultats, supposés (bien entendu) tous positifs, que nous allons noter R. Rien n'étant parfait, R ne coïncide pas forcément exactement avec D+ (cf. patatogramme ci-dessous).
|
|
|
Résultats d'une recherche d'information |
En pratique, donc, le système « oublie » parfois des documents qui vous auraient intéressés (partie de D+ qui n'est pas recouverte par R), et vous sort en revanche des documents qui se révèlent être en-dehors de votre centre d'intérêt (partie de R qui recouvre une partie de D–). Dans le jargon de la recherche d'information, les « bons » résultats (la partie de R qui coïncide bien avec D+, autrement dit, les bonnes réponses) sont appelés des vrais positifs ; et les documents sans intérêt pour vous que le système ne vous a, à juste titre, pas présentés (la partie de D– qui n'est pas recouverte par R) sont appelés des vrais négatifs. Au contraire, les résultats ramenés par le système alors qu'ils sont en réalité sans intérêt pour vous (partie de R qui recouvre D–) sont appelés des faux positifs, puisqu'ils sont classés comme positifs, mais par erreur. Et symétriquement, les documents intéressants que le système a oublié de ramener (partie de D+ non couverte par R) sont appelés des faux négatifs. En résumé :
| VP | = | R | ∩ | D+ |
| VN | = | R' | ∩ | D– |
| FP | = | R | ∩ | D– |
| FN | = | R' | ∩ | D+ |
(où R' dénote le complémentaire de R dans D).
Les termes de précision et de rappel formalisent les notions correspondant à la capacité du système de recherche d'information (1) à ne pas trop vous présenter de résultats sans intérêt (plus le taux de résultats pertinents est élevé, plus on considère la recherche d'information comme « précise »), et (2) à celle à ne pas trop oublier de documents intéressants (plus le système réussit à retrouver de documents positifs, plus il a de « rappel » relativement à D+). On définit donc la précision comme le nombre de documents intéressants dans R rapporté au nombre total de documents dans R ; et le rappel comme le nombre de documents intéressants dans R rapporté au nombre total de documents positifs (dans D+). Ce qui s'écrit encore :
| Prec | = | | R ∩ D+ | | / | | R | |
| Rapp | = | | R ∩ D+ | | / | | D+ | |
ou encore :
| Prec | = | VP | / | (VP+FP) |
| Rapp | = | VP | / | (VP+FN) |
Il existe également deux notions complémentaires de la précision et du rappel, que vous aurez sans doute tendance à utiliser si vous êtes du genre à voir les verres à moitié vides plutôt qu'à moitié pleins : ce sont les notions de taux de silence et de taux de bruit. Alors que le rappel mesure ce que la recherche d'information n'oublie pas, le silence mesure ce qu'elle oublie ; et alors que la précision mesure ce qu'elle ramène d'intéressant, le bruit mesure ce qu'elle ramène d'inintéressant. En d'autres termes :
| Silence | = | | R' ∩ D+ | | / | | D+ | |
| Bruit | = | | R ∩ D– | | / | | R | |
ou encore :
| Silence | = | FN | / | (VP+FN) |
| Bruit | = | FP | / | (VP+FP) |
Notez bien que dans les systèmes de recherche d'information à base de mots-clés, et qui sont à l'état de l'art actuel (ex. moteurs de recherche sur internet), il n'existe pas de cas où le système « oublie » réellement des documents contenant les mots-clés que vous demandez, ni de cas où le système vous donne par erreur des documents ne contenant pas vos mots-clés. Bref, il n'y a pas de grossière erreur algorithmique.
Ceci n'empêche pas l'usager de ressentir souvent une certaine insatisfaction devant les résultats : vous l'avez constaté comme tout le monde, vous récupérez souvent des brassées de documents qui ne vous intéressent pas du tout, alors que vous avez le sentiment de passer à côté de documents qui parlent exactement de ce que vous cherchez.
L'origine de cette inadéquation entre vos attentes et les résultats de la recherche n'est pas informatique à proprement parler. Elle a parfois à voir avec des incompatibilités de normes d'encodage, par exemple lorsque vous cherchez « fédération » et qu'un document encodé en LaTeX ancienne mode, en Postscript, ou en RTF, vous échappe parce qu'il transcrit le caractère « é » par une combinaison du type « \'e », « e' », ou « \'e9 », et contient donc à la place une chaîne « fe'de'ration » ; ou encore lorsque vous cherchez une référence au royaume mythique de « Laputa » et que suite à des transcriptions spécifiques de certains espacements typographiques, vous récupérez des pages concernant le film uruguayen « En la puta vida ».
Cependant, le plus souvent, l'inadéquation vient plus simplement de vous. Plus précisément, elle tient au choix des mots-clés que vous utilisez pour la recherche : vous connaissez votre thème d'intérêt, et certains mots-clés vous semblent « naturellement » refléter très exactement ce thème d'intérêt, alors que ce n'est pas le cas. Comment cela est-il possible ? Examinons quelques cas concrets.
Bruit :
Vous cherchez des informations sur les chats (mammifères félins domestiques), et vous commencez tout naturellement par chercher « chats » sur Google. Vous obtenez 11 millions de résultats dont la plupart concernent des forums de messagerie instantanée sur internet. Si vous cherchez à préciser votre recherche en tapant « sales chats », ça ne s'arrange pas : vous trouvez encore un demi-million de pages web qui parlent de « sales tips, success stories, real-time sales chats, top-level resources (...) ».
N.B. Si vous lancez Google en français, vous obtenez les mêmes résultats, mais il est vrai qu'ils sont alors réordonnés en pondérant plus fortement les pages parlant de mammifères domestiques — vous en trouvez donc un peu plus dans les premières pages de résultats.
Vous cherchez des informations sur les centrales électriques : vous tapez donc « centrale » dans un moteur de recherches. Vous recevez une foule d'informations sur le journal La centrale des particuliers, sur l'École centrale de Paris, la Centrale des Syndicats du Québec, sur la Bibliothèque centrale de l'école polytechnique fédérale de Lausanne, les pays d'Asie centrale, l'Imprimerie centrale du Luxembourg, la Banque centrale de Tunisie, sur l'organigramme de l'administration centrale du MENESR, les détenus de la maison centrale d'Arles, etc. Eh oui : le mot « centrale » sert à plein de choses, on ne se doutait pas à quel point.
Vous faites une maîtrise de syntaxe sur la proposition relative ; vous cherchez donc candidement « relative » sur Google. Vous obtenez 60 millions de résultats qui parlent de toutes sortes de choses, de la Geneva convention relative to the treatment of prisoners of war à la notion d'adresse relative en informatique ...
N.B. La bonne réaction : après avoir consulté les deux ou trois premières dizaines de résultats, vous retournez voir votre directeur de recherche en lui disant : « il n'y a rien comme documentation sur la relative ».
Silence :
Vous cherchez des fiches descriptives donnant des informations précises sur un certain nombre de champignons (pour savoir par exemple lesquels sont vénéneux, lesquels sont comestibles, lesquels sont psychotropes ...) Vous cherchez donc « champignon » dans un moteur de recherche. Résultat : vous passez à côté d'un certain nombre de fiches extrêmement détaillées contenant des informations spécifiques sur le bolet de satan, le lactaire sanguin ou le psilocybe lancéolé, et ne mentionnant pas une seule fois le mot « champignon ». En effet, dans les discours très spécifiques sur un sujet bien précis, il est fréquent que le recours au terme générique soit aussi superflu qu'il le serait dans un discours n'ayant rien à voir avec ce sujet (pour caricaturer : vous n'avez aucune chance de voir employé le mot « alimentation » dans un livre de cuisine).
Vous faites une maîtrise de sociolinguistique sur l'utilisation d'une langue régionale, le créole, dans des communautés d'usage comme celle du milieu sportif. Initié aux subtilités de Google, vous tapez entre guillemets (recherche de chaîne exacte) : « "exemples d'utilisation du créole dans les clubs de football" ». Vous ne trouvez aucun résultat.
N.B. La bonne réaction : vous allez voir votre directeur de recherche en lui disant : « il n'y a strictement aucune documentation sur mon thème de recherche ».
Comme on peut le voir à travers ces exemples, le manque de pertinence de l'ensemble des résultats vient souvent d'un mauvais choix du ou des mots-clés utilisés pour effectuer sa recherche. Dans certains cas, un mot utilisé sans ambiguïté dans un domaine particulier (ex. du mot « relative » dans un cours de linguistique) se révèle servir à de nombreux autres usages dans de nombreux autres domaines. C'est le problème auquel on se réfère fréquemment, dans le domaine de la recherche d'information en langue naturelle, sous le nom d' « ambiguïté des termes ». Il est clair, on peut le noter au passage, que l'ambiguïté dont il s'agit n'est pas une ambiguïté du mot en discours (dans un cours de linguistique, on n'éprouve jamais le besoin de préciser à chaque fois de quelle « relative » il s'agit), mais surgit dans un contexte artificiel qui supprime les spécificités de domaines en classant tout dans un même grand sac.
Quoiqu'il en soit, il vous faut expérimenter des moyens de mieux cibler votre recherche afin de récupérer un ensemble de résultats exploitable (c'est-à-dire contenant un nombre convenable de résultats utiles, qui ne soient pas noyés dans les résultats inutiles). Voici quelques conseils élémentaires :
pour lutter contre le bruit : tentez de rajouter des mots-clés qui spécifient l'emploi du terme qui vous intéresse particulièrement ; par exemple, au lieu de mettre seulement « relative », essayez « proposition relative », « pronom relatif », « relative clause », « betrekkelijke bijzin », etc. Au lieu de « centrale » toute seule, mettez « centrale électrique », « centrale nucléaire », « centrale hydraulique », « centrale thermique », etc. Bref, pratiquez le rétrécissement des contextes.
Ici quelques astuces de « recherche avancée » présentes (maintenant) sur la plupart des systèmes de recherche peuvent se révéler très utiles :
la première est la recherche de chaîne exacte, qui consiste à restreindre les résultats de recherche à ceux contenant les mots-clés exactement dans l'ordre où vous les spécifiez (ce type de recherche s'indique généralement en entourant la chaîne exacte de guillemets anglais : "..."). Ainsi, si vous faites une recherche sur « "proposition relative" », vous retrouvez les 29000 documents parlant précisément de « proposition relative », avec les deux mots contigüs, et dans cet ordre, et pas tous les documents (2,5 millions) contenant les deux mots quelque part dans le texte, l'un ici, l'autre là (ce qui est très fréquent en français, avec entre autres toutes les « proposition[s] (de loi, du comité central du PCC, etc.) relative[s] à ... »)
la seconde est la recherche booléenne, qui vous permet de combiner vos termes de recherche avec les opérateurs de la logique des propositions : les opérateurs binaires ET, OU et l'opérateur unaire NON. Rechercher « chat ET noir », c'est rechercher tous les documents contenant à la fois le mot « chat » et le mot « noir » ; rechercher « chat OU noir », c'est rechercher tous les documents contenant soit le mot « chat », soit le mot « noir », soit les deux ; rechercher « NON noir », c'est rechercher tous les documents ne contenant pas le mot « noir ».
N.B. En termes formels, les opérateurs booléens ne sont bien sûr pas des opérateurs sur les termes eux-mêmes mais sur les propositions logiques construites à partir de ce terme, de la forme « le document contient le terme T ». On peut également traduire ces opérateurs, en termes de théorie des ensembles, par l'intersection, l'union, et le complémentaire. Ainsi, si on note R(T) l'ensemble des documents contenant le terme T, alors on définit les opérateurs par :
R (chat ET noir) = R(chat) ∩ R(noir) R (chat OU noir) = R(chat) ∪ R(noir) R ( NON chat ) = ( R(chat) )'
La recherche booléenne peut vous permettre de construire une expression qui vise à « serrer au plus près » les emplois d'un terme qui vous intéressent. Ainsi, si vous repérez, au fil de vos premières recherches, que les documents sur les centrales génératrices d'électricité parlent dans la plupart des cas de « centrale électrique », « centrale thermique », « centrale hydraulique » ou « centrale nucléaire » ; ou encore de « centrale » puis de « génération » ; alors que par ailleurs un indice assez sûr pour indiquer que vous faites fausse route est le fait que le document parle de « centrale syndicale » ou de « centrale » puis (quelque part dans le document) de « détenus », alors vous pouvez refléter ces règles d'expérience en construisant l'expression complexe : « centrale ET (électrique OU thermique OU hydraulique OU nucléaire OU génération) ET (NON syndicale) ET (NON détenus) ».
N.B. Dans Google, le ET est implicite (« centrale thermique » s'interprète automatiquement comme « centrale ET thermique ») ; le OU se note OR (comme dans « centrale OR génération ») ; enfin le NON se note par un signe - (moins, tiret, ou encore trait d'union) placé devant le mot-clé à exclure. Ainsi l'expression ci-dessus se noterait-elle : « centrale électrique OR thermique OR hydraulique OR nucléaire OR génération -syndicale -détenus ».
Outre ces deux formes principales de recherche « avancée », il existe encore quelques astuces permettant de préciser la recherche.
Notez tout d'abord que dans le cas de Google, les mots-outils très fréquents sont systématiquement retirés de la recherche ; en effet, dans le cas général, ils augmentent le temps de recherche sans avoir de réel caractère discriminant (par exemple, le mot « de » étant présent dans à peu près tout texte comportant plus de trois phrases, dans n'importe quelle langue latine, il est peu vraisemblable qu'il vous permette d'affiner réellement votre recherche en éliminant une partie significative des résultats d'un quelconque ensemble de documents). Il existe des cas où la prise en compte de ces petits mots peut se révéler tout à fait importante : ce sont les situations où l'on fait une recherche de chaîne exacte sur un syntagme précis contenant certains de ces petits mots — par exemple « sémantique de la phrase ». Google prend automatiquement ce cas de figure en compte lorsque vous entourez l'expression entière de guillemets anglais. Dans les autres cas, il existe encore un moyen de le forcer à intégrer « de » et « la » à la recherche : en ajoutant un signe « + » devant : « +de », « +la ». Mais encore une fois, cela risque de se révéler inutile.
Vous pouvez encore préciser votre recherche en posant des restrictions sur les domaines internet dans lesquels elle doit se dérouler. Ainsi, si vous avez noté que la proportion de documents intéressants que vous récupérez depuis des sites dont l'adresse internet se termine par .com est extrêmement faible, vous pouvez les exclure d'emblée de la recherche en ajoutant le terme « -site:com ». À un niveau de localisation bien plus précis, si vous cherchez par exemple tous les documents qui parlent d'apprentissage de grammaires dans les publications de l'équipe de recherche sur l'apprentissage automatique de Lille 3, vous pouvez faire une recherche sur : « learning grammars site:univ-lille3.fr » ou « apprentissage grammaires site:univ-lille3.fr ».
Vous pouvez encore, si vos termes de recherche se trouvent par hasard correspondre à des mots existant dans des langues différentes — ce qui vous conduit à un mélange de résultats sans aucun rapport entre eux —, spécifier la langue des documents que vous recherchez : pensez par exemple aux « sales chats » mentionnés plus haut ; ou encore, essayez de faire une recherche sur le concept de l'Être dans la philosophie allemande, et de taper « Sein » (l'Être, en allemand) sans spécifier la langue ... Pour spécifier la langue d'une recherche, vous devez utiliser le formulaire de recherche avancée, disponible sur la plupart des moteurs de recherche, qui vous permet par ailleurs de préciser un certain nombre d'autres subtilités, que vous découvrirez au fur et à mesure.
pour lutter contre le silence : tout d'abord, êtes-vous sûr d'avoir bien conçu votre espace de recherche avant même d'avoir posé la question ? Dans beaucoup de cas, les problèmes de silence que rencontrent les étudiants débutant une recherche d'information sont dûs non à une mauvaise manipulation des outils de recherche, mais, plus profondément, à une conception inadéquate de ce en quoi doit consister une recherche de bibliographie sur un sujet de recherche.
Illustrons l'erreur la plus répandue par un exemple : vous voulez faire une recherche sur l'usage des formes de politesse en français des Antilles (avec un point de vue sociolinguistique comparatif, s'appuyant sur la description de l'usage des formes d'adresses qui est fait par les locuteurs originaires de France métropolitaine). Que trouvez-vous si vous cherchez des informations (tant sur Google que sur une base de données bibliographiques comme MLA) sur les termes : « tutoiement français antilles » ? Réponse : rien (je veux dire : rien de scientifique ; je ne parle pas des choses du genre « quelques indications pour les touristes se rendant aux Antilles », qu'il faut bien se garder d'inclure dans une bibliographie sous peine de passer soi-même pour un touriste !)
Pourquoi n'y a-t-il rien ? Tout simplement parce que cette requête, très restrictive, ne peut recouper qu'un document extrêmement spécifique — tellement spécifique en fait que cela revient à chercher son mémoire déjà tout fait ! (ce n'est pas ce que vous souhaitez, bien entendu). Un tel document n'est pas disponible, naturellement — et c'est heureux, sinon cela voudrait dire que votre travail de recherche a déjà été traité, que vous pouvez jeter votre sujet à la poubelle et en chercher un autre.
Chercher une bibliographie utile ne veut pas dire chercher des textes qui traitent très exactement de la même chose que soi, avec très exactement le même point de vue ! Cela veut dire : chercher des travaux antérieurs qui vont éclairer son propre travail :
| ‣ | soit parce qu'ils sont plus généraux : | par exemple, un ouvrage sur les usages des formes d'adresse en général ; |
| ‣ | soit parce qu'ils étudient un même objet sur un autre corpus : | par exemple, un article sur les formes d'adresse en français du Québec, ou en portugais du Brésil ; |
| ‣ | soit parce qu'ils étudient un même objet avec d'autres méthodes : | par exemple, un mémoire sur le tutoiement et le vouvoiement d'un point de vue de linguistique énonciative ; |
| ‣ | soit parce qu'ils utilisent les mêmes méthodes pour étudier un autre objet : | par exemple, un article sur le vocabulaire de la famille et de la parenté en français des Antilles ; |
Bref, il y a plein de raisons de s'intéresser à des travaux de recherche antérieurs — qu'ils aient regardé la même chose que vous à travers d'autres lunettes, ou autre chose que vous à travers les mêmes lunettes — mais une chose est certaine : il ne sert à rien de chercher un doublon de son propre travail de recherche. Avant de commencer les aspects techniques de la recherche bibliographique, essayez donc de mettre votre imagination à contribution pour réfléchir aux types de travaux qui auraient pu être réalisés, et qui vous seraient utiles, et faites-vous à l'avance une liste de directions dans lesquelles vous pourrez aller à la pêche aux idées.
Lorsque vous avez une idée du type de document que vous aimeriez bien récupérer, essayez également de vous mettre à la place de celui ou ceux qui ont pu le rédiger, et de vous demander comment vous auriez formulé, à leur place, le sujet qui vous intéresse.
Pour illustrer ce point, reprenons un exemple déjà cité : un étudiant cherche des exemples d'utilisation des langues régionales dans certains contextes de communication particuliers (au cours des jeux, dans le milieu sportif). Il tape dans Google la requête suivante : « "exemples d'utilisation de la langue régionale" ». Surprise : il n'y a rien.
Retournons en effet le problème : quand cet étudiant rédigera son mémoire, est-il probable qu'il y écrive, à un moment ou à un autre, le syntagme : « exemples d'utilisation de la langue régionale » ? Non, bien sûr. D'abord parce que la langue régionale sur laquelle il se penche sera vraisemblablement dénommée (il est rare qu'un travail étudie concrètement plusieurs langues régionales à la fois, ou un concept abstrait de « langue régionale » indépendant de tout contexte réel ; en outre, la dénomination d'une langue comme « langue régionale » est tout à fait liée à son étude dans une mise en contexte particulière — celle de son rapport à une langue officielle d'un certain état — aucune langue n'étant intrinsèquement « régionale »). Ensuite, tout simplement parce que même en citant des exemples d'utilisation de l'alsacien (par exemple) dans un travail, on n'est jamais dans une situation où l'on écrit : « exemples d'utilisation de l'alsacien » — puisqu'on est justement dedans ! On écrit des choses comme : « l'alsacien est très vivant dans le milieu viticole », ou « l'entretien suivant s'est déroulé dans sa plus grande partie en alsacien » ... Un syntagme comme « exemples d'utilisation de ... » n'est pas du type de ceux qui se rencontrent réellement dans le texte cherché ; c'est un syntagme descriptif d'un certain type de documents qui est donné avec un point de vue extérieur. Autant essayer de retrouver le mot « roman gothique » dans le texte intégral des Hauts de Hurlevent !
Si vous pensez avoir bien ciblé le type de documents qui pourraient vous être utiles dans votre propre travail, avoir trouvé les formulations correctes, et que vous n'obtenez malgré tout que pas ou peu de résultats, voici quelques pistes que vous pouvez explorer pour tenter de râtisser plus large :
Essayez plusieurs formes fléchies d'un mot ; par exemple, si l'un de vos termes de recherche est un nom, essayez de le mettre au singulier et au pluriel ; si c'est un verbe, n'essayez pas seulement l'infinitf : tentez aussi les formes les plus utilisées (notamment la troisième personne, au présent et à l'imparfait, et le participe passé). N'oubliez pas que la majorité des moteurs de recherche n'effectue aucune lemmatisation par défaut (c'est-à-dire : ne sait pas relier « trouvait » ou « trouvés » à « trouver »).
Essayez différents termes qui pourraient également se trouver dans le type de document que vous cherchez. Sans parler de « synonymes » (de toute façon, dans les genres descriptifs précis, il n'y a pas de synonymie), il s'agit d'imaginer, plus généralement, quels sont les termes qui sont souvent cooccurrents avec ceux auxquels vous avez pensé au début : ils vont vous permettre de « rabattre » dans votre filet certains documents qui pour une raison ou une autre n'emploient pas ceux-ci. Ainsi, si vous faites une recherche sur le slavon, vous aurez intérêt à rechercher également « vieux slave », et même « vieux bulgare » (N.B. Nous sommes d'ailleurs là dans un domaine ou la co-référence ne va pas forcément de pair avec la co-occurrence, car les dénominations reflètent des parti-pris ... mais c'est un autre sujet).
Si vous êtes en panne d'imagination, vous pouvez essayer d'utiliser le constructeur interactif de cartes du web que propose le métamoteur de recherche KartOO : http://www.kartoo.com (cf. ci-dessus, §1.3). Il vous proposera automatiquement des mots-clés corrélés avec votre recherche précédente.
N'hésitez pas à répéter votre recherche en utilisant des mots d'une autre langue que vous savez lire à peu près correctement : il serait dommage de se passer de documents potentiellement précieux en anglais, en espagnol ... simplement parce que vous n'avez pas pensé à formuler vos termes de recherche dans une autre langue que le français ! Peut-être ne savez-vous pas comment exprimer telle ou telle notion dans une langue donnée ? Raison de plus pour effectuer un petit travail préalable consistant à rechercher les traductions de vos thèmes d'intérêt dans toutes les langues que vous êtes capable de lire. Ce travail vous sera de toute façon utile, et vous entamerez déjà, en le faisant, votre recherche d'information.
Pour trouver les équivalents des termes qui vous intéressent dans d'autres langues, le mieux est de commencer par un bon dictionnaire bilingue. Si vous n'en avez pas sous la main, vous pouvez aussi commencer par utiliser des dictionnaires bilingues en ligne disponibles sur la Toile, mais ils ne sont en général pas aussi détaillés, ne recouvrent pas les subtilités des domaines d'emploi spécialisés, et ne donnent pas des exemples d'emploi. Or attention : il vaut souvent mieux partir sur pas de terme équivalent du tout, que sur une équivalence fausse (par exemple énoncé — au sens linguistique — se dit en anglais utterance ; si vous partez sur l'équivalence donnée en premier par un mauvais dictionnaire, exposition, vous ne trouverez jamais ce que vous cherchez).
À titre indicatif, voici quelques bons dictionnaires en ligne, classés selon la langue susceptible de vous intéresser :
| ‣ | allemand-anglais-français : | LEOs Wörterbuch (dictionnaire collaboratif, édité par l'Université Technique de Munich) |
| http://dict.leo.org | ||
| Ce dictionnaire est en partie construit par ses utilisateurs : lorsqu'un utilisateur a l'impression qu'une information manque, et que finalement il la trouve, il peut la rajouter. Grâce à ce procédé, le dictionnaire LEO propose souvent de très utiles traductions de constructions entières (et pas seulement mot pour mot). | ||
| ‣ | français-anglais : | Grand Dictionnaire Terminologique (édité par l'Office Québécois de la langue française) |
| http://www.granddictionnaire.com | ||
| Le dictionnaire français-anglais le plus complet à ma connaissance sur Internet : il donne des précisions sur une vaste palette de domaines d'usage spécifiques. | ||
| ‣ | anglais-chinois : | « 中文 » — Zhongwen.com (Chinese Characters and Culture, site créé par un professeur d'économie américain sinisant, Rick Harbaugh) |
| http://www.zhongwen.com | ||
| La recherche de mots dans un dictionnaire chinois est toujours rendue fastidieuse, pour nous qui sommes habitués à l'alphabet latin, par le problème de l'entrée du premier caractère (selon qu'on doit le chercher par la clé, par le nombre de traits, par la phonétique ... la recherche peut devenir un véritable casse-tête chinois). Le site « zhongwen.com » rend cet accès aisé grâce au principe de l'hypertexte : on peut chercher un caractère par un équivalent anglais (c'est par là que l'on commence si l'on ne connaît même pas le début du mot chinois), par la transcription phonétique « pinyin » (si l'on connaît la prononciation mais pas l'écrit), par la clé ou par n'importe quel autre composant élémentaire (si l'on connaît l'écrit mais pas la prononciation ou le sens). Puis on peut naviguer dans les familles de dérivés, et s'intéresser aussi bien à la composition externe (formation de mots avec ce caractère) qu'à la composition interne (formation de ce caractère par des constituants élémentaires qui interviennent également dans d'autres). On peut donc naviguer autant que nécessaire (et en général, plus que nécessaire) dans le réseau sémantique « naturel » que constitue l'écriture chinoise. Le site privilégie l'écriture traditionnelle mais les équivalents en écriture simplifiée sont également fournis. | ||
| ‣ | portugais-anglais-français : | Dicionário de Termos Linguísticos (édité par l'AIT, Association d'Information Terminologique du Portugal) |
| http://www.ait.pt/recursos/dic_term_ling/ | ||
| Glossaire de termes de linguistique portugais, avec des définitions dans cette même langue. Pour chaque terme des équivalents anglais et français sont donnés. | ||
| ‣ | autres langues : | Pour trouver un dictionnaire pour une langue donnée, un bon point de départ est toujours : « Your Dictionary » |
| http://www.yourdictionary.com | ||
| Page portail référençant des dictionnaires disponibles sur le web pour environ 300 langues. | ||
Une astuce qui porte assez souvent des fruits consiste également à effectuer une recherche sur le terme que vous connaissez, dans la langue A, en contraignant le système pour qu'il effectue sa recherche dans la langue B (ex. chercher les pages en italien contenant « word sense disambiguation »). Vous aurez peut-être ainsi la chance de tomber soit sur une page qui donne l'équivalence exacte en mentionnant le terme connu entre parenthèses, soit sur une page présentant le résumé d'un article ou d'un ouvrage en plusieurs versions dans des langues différentes, et qui contient entre autres votre terme. Dans ce contexte, vous serez souvent amené à utiliser la langue anglaise comme pivot ; donc vous gagnerez à commencer votre recherche d'équivalences par l'anglais.
Après cette phase de recherche des termes équivalents, il vous faudra tâtonner, à partir des « ilôts de confiance » que constituent les termes dont vous connaissez déjà la traduction, pour élargir votre connaissance des expressions et des tournures utilisées par l'autre langue. Ainsi, si vous savez comment dire « alternance codique » en anglais, vous saurez vraisemblablement bientôt, en lisant les documents que vous allez trouver, comment dire « tours de parole », car les articles parlant de l'une parlent également souvent des autres ... Plus vous lirez d'articles du domaine qui vous intéresse dans une certaine langue, plus vous comprendrez les expressions que cette langue emploie pour ce domaine ; et bien entendu, plus vous comprendrez, plus vous pourrez lire : c'est une rétroaction positive.
Surveiller les fréquentations des pages web
L'une des difficultés lorsqu'on manque d'expérience dans la recherche d'information sur la Toile (il en a déjà été question plus haut, notamment aux §1.4 et §6.2) est de savoir distinguer l'information sérieuse de l'information biaisée, piégée, tendancieuse, manipulatrice, ou simplement captatrice. On a vu qu'il n'existait pas de recette magique, puisqu'aucune autorité supérieure de certification ne « règne » sur Internet. Il existe cependant divers indices plus ou moins fiables, le plus simple à évaluer étant le fait que le document soit hébergé sur le serveur d'une institution scientifique (université ou organisme de recherche), d'autres faisant appel au « flair » rhétorique du lecteur.
Cependant, quoiqu'on fasse, le contenu textuel du document ne permet pas à lui seul d'éliminer tous les doutes dans tous les cas. Il est en effet possible (et même classique) qu'une information semblant idéologiquement neutre soit diffusée par une source travaillant à la diffusion d'une certaine idéologie, dans le seul but de « rabattre » des internautes non-avertis vers ses circuits d'information.
Dans de tels cas, l'un des critères les plus déterminants pour savoir si l'on a affaire à une source digne de confiance scientifique ou non est d'examiner le voisinage de la page pour voir à quel type de site elle appartient — et, le cas échéant, à quelle nébuleuse de sites celui-ci appartient.
Prenons un exemple : vous cherchez des documents sur les anciens cultes où l'on vénérait les arbres ; vous faites donc une recherche sur quelques mots-clés innocents, comme « anciens cultes arbres forêts ». Au fil des résultats, vous tombez sur une page mise en ligne sur le site www.terreetpeuple.com qui donne quelques informations assez détaillées sur d'anciennes divinités gauloises.
« Terre et Peuple » est un mouvement fondé par un intellectuel d'extrême-droite, affilié d'abord au F.N., puis au M.N.R., représentant le mouvement « néo-païen » de l'extrême-droite française, militant pour une « reconquête identitaire » des « peuples européens » (dans les termes du jargon de cette mouvance politique). Ces idées n'empêchent pas certaines des publications de ce mouvement d'être solidement documentées, et donc vous trouverez sur une page web comme celle citée plus haut des renseignements factuels précis sur les religions des anciens celtes, comme vous les trouveriez sur un document émanant d'un site universitaire (d'ailleurs certains membres de ce type de mouvement sont des universitaires). Il est cependant évident qu'il serait totalement hors de propos de citer comme référence, dans un travail universitaire, une publication d'un mouvement politique d'extrême-droite.
Comment faire, donc, pour faire la différence entre une page qui dit que les Gaulois vénéraient les arbres et le dieu Lug, et émise par un site sérieux, et une page disant entre autres la même chose, mais émise par un site idéologiquement tendancieux ?
La réponse : il ne faut jamais ajouter une page web à sa bibliographie sans explorer un peu son voisinage.
Voisinage dans le site : il est bon de prendre le réflexe, lorsque l'on tombe sur un site par une page interne (et pas par la page d'accueil), de toujours aller visiter la page d'accueil pour voir comment le site se présente. Souvent, cette page est accessible depuis toutes les pages du site en cliquant sur un lien « Accueil » (ou « Home », ou « Startseite », ou n'importe quel autre équivalent). À défaut, on tombe souvent dessus en raccourcissant l'URL (l'adresse de la page web) : si le site utilise manifestement un nom de domaine spécifique (par exemple, http://www.revue-texto.net), ou un alias d'hôte spécifique (par exemple, http://creoles.free.fr), on coupera à la première barre oblique (sans compter celles du préfixe "http://", bien sûr) ; s'il est hébergé sur le domaine Internet d'un grand fournisseur (par exemple, http://www.geocities.com/Athens/Troy/1736/ sur Geocities), on coupera au point pertinent (chaque fournisseur a des schémas d'attribution d'URL particuliers ... on retrouve vite, de toute façon, en tâtonnant, l'URL de la page racine du site).
Souvent, un simple coup d'œil à la page racine du site permet de faire immédiatement le tri : si elle contient par exemple le mot Dieu, le mot identitaire, le mot PNL, ou le mot carte bleue, inutile de perdre plus de temps. Dans le cas où le site donne accès à une page du type « Présentation » ou « Qui sommes-nous ? », allez systématiquement y jeter un œil : cela sera utile souvent pour éliminer le site, parfois pour citer vos sources.
Voisinage du site sur la Toile : un autre critère essentiel est le voisinage du site dans le graphe orienté que constitue le web. Un site n'est jamais isolé : il pointe (le plus souvent) vers d'autres sites, et d'autres sites (presque toujours) pointent vers lui. Les liens hypertexte donnent ainsi une idée des « fréquentations » de chaque site : les liens « descendants » (sites vers lequel ce site pointe) reflètent les amis qu'il aimerait avoir ; les liens « ascendants » (sites qui pointent vers lui), ceux qui le reconnaissent comme ami. Les deux fournissent souvent des indices très intéressants.
Comment repérer les liens descendants ? — C'est très simple : en cliquant sur les liens (parties du texte soulignées en bleu). Certains sites regroupent souvent l'ensemble de leurs liens dans une page dédiée (qui s'appelle généralement ... liens) : une promenade dans cette page est dans ce cas très instructive. Ainsi, si on visite la page « Liens » du site « Terre et peuple » cité plus haut, on voit assez rapidement à quel genre de mouvance on a affaire.
Comment repérer les liens ascendants ? — C'est moins évident : ils ne sont pas inscrits dans le site lui-même (le gestionnaire du site peut recevoir des informations techniques, grâce au protocole HTTP, sur les sites web qui lui « font référence », mais celles-ci ne sont généralement pas à la disposition du public des visiteurs). En revanche, on peut retrouver la partie la plus stable et la plus émergente de ces liens ascendants en utilisant une astuce qui consiste à passer par Google. Ce moteur de recherche indexe en effet une large base de sites et garde mémoire des liens que ceux-ci tissent entre eux. On peut l'interroger sur ce critère : il faut utiliser pour cela le mot-clé link. Pour demander, par exemple, quelles pages pointent vers la page « http://ling.kgw.tu-berlin.de/semiotik/deutsch », on tape dans Google : « link:ling.kgw.tu-berlin.de/semiotik/deutsch ».
Les fréquentations d'un site web en disent souvent bien plus sur son positionnement réel (et tout au moins le disent bien plus clairement) que toutes les explications fournies par les auteurs eux-mêmes.
Qui est derrière un nom de domaine internet ?
Si vous avez vraiment du mal à discerner qui est à l'origine d'un site web, vous avez toujours la possibilité d'accéder à l'information concernant le titulaire de la propriété légale d'un certain domaine internet. L'usage internationalement répandu veut en effet que l'identité légale de celui qui a déposé la demande d'utilisation exclusive d'un certain nom de domaine auprès des enregistreurs accrédités (registrars), gérant les tables DNS (domaine name servers), soit publique et accessible à tous au travers d'une base de données appelée whois.
Ceci ne vous dit en général pas qui a rédigé précisément telle ou telle page web, mais cette ressource vous garantit qu'aucun site web ne puisse rester complètement anonyme. Pour les utilisateurs avertis, ce système offre la possibilité de détecter des connexions entre différents sites web (plusieurs noms déposés par la même personne, société ou association), ou entre un site web et une personnalité ou organisation connue par ailleurs.
Chaque enregistreur accrédité tient à jour, dans sa propre base whois, la liste de ses clients (personnes physiques ou morales ayant déposé un nom de domaine par son intermédiaire), mais offre également accès, sur un principe de parité, aux informations contenues dans les bases whois de tous les autres enregistreurs accrédités connus. Peu importe donc par lequel d'entre eux on entame une recherche de ce type.
Exemple d'enregistreur accrédité sérieux, offrant un accès à sa base whois : GANDI (http://www.gandi.net).
Repérer les expressions complexes utilisées dans un certain domaine
Les textes scientifiques ou techniques abondent en expressions complexes semi-figées (par exemple, composés du type N-de-N, N-Adj, ou V-N) qui se cristallisent en unités signifiantes dans leur domaine spécialisé. Grâce au corpus gratuit de plusieurs milliards de mots que constitue le web, et grâce aux outils de recherche dans ce corpus que constituent les moteurs de recherche (certes imparfaits et pas vraiment faits pour ça, mais néanmoins bien utiles), vous pouvez appréhender ce type d'expressions autrement que par votre simple intuition : vous pouvez en effet en quantifier l'usage.
Vous pouvez ainsi mesurer le degré de cohésion interne (sur le corpus du web) d'une expression composée, en rapportant le nombre de documents où elle est employée telle quelle, au nombre de documents où les mots qui la composent apparaissent indépendamment. Par exemple, si on recherche sur Google « alternance codique » (les deux mots, pas forcément contigüs), on trouve 632 résultats (au 1er février 2005). Si on recherche « "alternance codique" » (l'expression exacte), on trouve 601 résultats. La cohésion interne, sur le web, de l'expression alternance codique est donc de 95% (601/632=0,95). En faisant le même test sur l'expression grammaires d'unification, par exemple, on arrive à un degré de cohésion interne de 69% (532/762). Malheureusement, cette mesure devient d'autant moins significative que les mots entrant dans la composition de l'expression sont des mots très courants (car ils ont alors des chances de se trouver simultanément dans n'importe quel type de document, sans que ce soit leur emploi spécialisé qui est utilisé).
La plupart des expressions composées sont dissymétriques : l'un des mots est fortement lié à l'autre, alors qu'il n'en est pas de même dans l'autre sens. Ainsi « lurette » apparaît presque toujours dans l'expression « belle lurette », alors que « belle » apparaît dans une foule d'autres contextes. Cette dissymétrie peut s'évaluer ; on peut mesurer, sur le web, ce qu'on peut convenir d'appeler la dépendance d'un mot par rapport à un autre dans une expression, et qu'on définit comme le nombre de fois où le mot A apparaît en conjonction avec le mot B, rapporté au nombre de fois où il apparaît, au total. Ainsi, le mot « codique » apparaît en tout 1100 fois sur le web, dont 601 fois dans l'expression « "alternance codique" » ; il a donc un degré de dépendance à cette expression de 54% (ce qui est beaucoup, comparé aux mots les plus courants de la langue générale). Pour donner une idée de ce que cette variable permet de mesurer, on peut mentionner sa valeur pour les expressions « alternance codique », « grièvement blessé », « belle lurette », « centrale nucléaire », et « pomme de terre » :
| Dépendance de alternance ... | ... de codique ... | ... dans alternance codique | ||
| moins de 1% (1 360 000) | 54% (1 100) | (601) | ||
| Dépendance de grièvement ... | ... de blessé(e)(s) ... | ... dans grièvement blessé(e)(s) | ||
| 69% (96 900) | 10% (634 000) | (67 500) | ||
| Dépendance de belle ... | ... de lurette ... | ... dans belle lurette | ||
| moins de 1% (15 400 000) | 87% (83 100) | (72 700) | ||
| Dépendance de centrale ... | ... de nucléaire ... | ... dans centrale nucléaire | ||
| moins de 1% (15 100 000) | 10% (1 030 000) | (103 000) | ||
| Dépendance de pomme ... | ... de terre ... | ... dans pomme de terre | ||
| 28% (930 000) | 2% (10 700 000) | (264 000) |
Ces résultats reflètent bien l'autonomie relative de ces mots par rapport aux expressions considérées. Autant, dans les cas les plus nets, lurette ou grièvement sont très majoritairement utilisés dans le contexte de ces expressions (grièvement a une dépendance un peu moindre car il s'applique aussi à brûlé ...) ; autant dans le cas de pomme de terre, par exemple, on voit que chacun des deux mots vit sa vie indépendamment de l'expression composée (même si celle-ci est également très utilisée).
Retrouver une référence perdue
Vous avez lu quelque part il n'y a pas longtemps que les « US twin deficits threaten global economic stability », et vous avez parlé de ça à votre tante et à votre beau-père. Ceux-ci ont immédiatement répondu que vous aviez dû voir ça sur le site web d'un parti trotskiste séditieux, ou dans le bulletin Socialist Worker, et que ce n'était pas sérieux. En fait, c'est le Global Policy Forum (une organisation consultative des Nations Unies) qui le dit, mais vous ne vous en souvenez plus exactement.
Vous êtes tombé l'autre jour sur un article qui vous a semblé intéressant sur les racines africaines du créole, et vous l'avez enregistré sur votre disque dur ; mais maintenant qu'il s'agit de le citer, vous vous apercevez que vous n'avez pas noté l'URL où vous l'avez récupéré. En plus, vous vous mettez à douter (après avoir lu ce guide, peut-être ?) des étais scientifiques de l'article et vous voudriez reprendre un peu la page web pour en examiner les liens et voir sur quelles sources il s'appuie. Mais où était-il, déjà ?
Dans ces deux cas, vous êtes face à un même problème : comment faire pour retrouver la source perdue d'une citation, ou l'adresse perdue d'un document ? Vous devez retrouver une source à partir d'un contenu.
Pour cela, vous pouvez faire une recherche englobant le plus grand nombre possible de mots dont vous vous souvenez : plus vous ajoutez de mots du document d'origine, plus vous avez de chances de retomber dessus (il est rare que deux documents emploient exactement la même formulation, même s'ils parlent de la même chose).
Si vous avez sous les yeux le texte exact dont vous voulez retrouver la source, le mieux est encore de rechercher, en expression exacte (entre guillemets anglais), une ou deux phrases du document d'origine, reprises mot pour mot. S'il s'agit bien d'un texte que vous avez trouvé sur la Toile, cette méthode vous garantit avec une quasi-certitude de le retrouver (que deux textes écrits indépendamment aient deux phrases exactes en commun est en effet extrêmement improbable).
Anecdotiquement, on peut noter que cette méthode rend définitivement dépassée une certaine forme de plagiat qui consiste à copicoller bêtement un texte trouvé sur Internet dans un document qu'on est supposé rédiger soi-même : ce que Google a trouvé, Google peut le retrouver. De nos jours, il n'y a plus que (certains) étudiants de début de première année de DEUG qui n'ont pas encore compris cela (et quelques autres rares exceptions). Pour plagier intelligemment, il faut récupérer des informations de plusieurs sources, les synthétiser, les reformuler ... et quand on arrive à faire ça, finalement, on fait déjà la moitié du travail de recherche : ce n'est plus du plagiat, c'est de l'érudition, et c'est considéré avec approbation par l'institution universitaire. Il ne reste plus qu'à avoir des idées.
Retrouver un document dont le lien est périmé
La méthode de la recherche de chaîne exacte peut également vous servir dans une autre situation : celle où vous cherchez à retrouver le nouvel emplacement d'un document dont le lien est périmé. La Toile est en effet un réseau extrêmement mouvant, et une URL valable à un moment donné peut très bien, quelques mois après, ne plus mener à rien — soit parce que le document n'est plus disponible, soit parce qu'il a changé d'adresse suite à une réorganisation du site (changement de la partie droite de l'URL) ou à un changement d'hébergeur (changement de la partie gauche de l'URL).
Cette situation est extrêmement fréquente : par analogie avec les atomes des éléments radioactifs, on dit que les pages web ont une faible demi-vie. La nécrose de portions entières de la Toile est d'ailleurs un phénomène qui commence à être bien connu des chercheurs en recherche d'information et qui a déjà fait l'objet d'études spécifiques (cf. par exemple « Sic transit gloria telae: Towards an understanding of the web decay », présenté à la treizième International World Wide Web Conference par des chercheurs d'IBM, Bar-Yossef, Broder et Kumar).
Lorsqu'une page web indexée a changé d'adresse, donc, un bon moyen de la retrouver est d'utiliser la méthode mentionnée ci-dessus pour retrouver l'emplacement d'un document dont on ne connaît pas l'adresse : faire une recherche de quelques mots très significatifs, ou mieux, de phrases entières, en chaîne exacte, sur un moteur de recherche.
Le cas de figure le moins favorable est celui où la page considérée a réellement disparu : soit elle n'est plus disponible du tout sur le Web, soit elle n'est plus indexée. Dans ce cas vous n'avez plus aucun moyen d'en accéder à une version actuelle.
Si malgré tout vous avez besoin de retrouver la page que vous cherchez, fût-ce dans une version passée, vous avez encore deux chances d'y arriver :
La première possibilité est celle où la page n'est plus disponible à l'adresse référencée, mais où elle se trouve encore dans le miroir-cache de Google : ce moteur de recherche archive en effet les pages qu'il indexe sur un miroir local. Dans le cas où la page recherchée a disparu, mais où Google ne le « sait » pas encore (son robot « crawler » n'est pas repassé vérifier ce lien entretemps), une copie exacte de la page peut être récupérée à partir de l'archive de Google, en cliquant sur le lien « En cache » (« Cached » dans la version anglaise). Cette méthode est sûre (toutes les pages indexées par Google sont archivées), mais n'a pas une grande durée de validité ; car dès que le robot de Google sera repassé sur le lien et aura constaté qu'il n'est plus valide, la copie disparaîtra également de l'archive. Le but de Google n'est en effet pas de conserver une archive éternelle du web, mais d'en donner un reflet le plus actualisé possible. Pour qu'une page disparaisse du cache de Google, il doit donc s'écouler un temps qui dépend de la fréquence avec laquelle le robot retourne périodiquement visiter le lien : cela peut être quotidiennement pour les pages les mieux classées (les sites les plus référencés), ou prendre plusieurs semaines pour les « petites » pages. Quoi qu'il en soit, ce n'est pas éternel.
La seconde — et dernière — chance que vous avez de trouver une page qui a existé dans le passé, mais qui n'est plus disponible, est d'essayer de la retrouver sur le site du projet Archive.org, the Wayback Machine (http://www.archive.org). Ce projet a bien pour but, lui, de créer une archive éternelle du web : ses robots passent sur des pages et les archivent dans le but de les garder indéfiniment (sauf exigence contraire de l'auteur). Malheureusement, il ne dispose pas de ressources infinies, au regard de l'immensité de la tâche : il ne peut donc pas se permettre de passer archiver autant de pages web, et aussi souvent, que Google. Vous pouvez donc essayer cette solution, mais sans être sûr de retrouver la page que vous cherchez : soit parce que le site n'aura pas été pris en compte par l'archiveur automatique, soit parce qu'il y sera passé avant ou après la période d'accessibilité de la page. Typiquement, le robot d'archive.org ne passe « visiter » les sites d'importance moyenne qu'une dizaine de fois par an ; donc pour qu'une page particulière s'y trouve, il faut qu'elle soit restée disponible dans une version stable, et à une URL stable, pendant plusieurs mois : cela a donc des chances de marcher dans le cas, par exemple, du site d'une équipe de recherche qui a disparu en tant que telle, mais pas, sauf coup de chance, pour retrouver la page d'une chronique quotidienne d'un jour particulier sur le site d'un « blog » ou d'un journal.
Contact : |
Pascal Vaillant |
( ) |